今天用我老掉牙的 MacBook Pro 2015 跑 IDEA 时,感觉略卡,于是在网上找了一些教程来优化它的启动和运行速度。 遇到问题 有不少网友提到的一个措施是修改 IDEA 自身运行的 Runtime,即 JDK 版本。也决定试一下看看效果,于是安装了 Choose Runtime 插件,然后将默认的 JetBrains Runtime 由 IDEA 自带 JDK 11 换成了我自己安装的 JDK1.8.0_271,然后……IDEA 就再也起不来了,启动就报如下这个错误: Unsupported Java Version Java 11 or newer is required to run the IDE. Please contact support at https://jb.gg/ide/critical-startup-errors Your JRE: 1.8.0_271-b09 x86_64 (Oracle Corporation) /Library/Java/JavaVirtualMachines/jdk1.8.0_271.jdk/Contents/Home/jre 解决方法 想办法进设置 Runtime 的地方,将配置再改回来。 但并没有找到办法进设置。失败 想办法找到存储这个配置项的配置文件,手动修改回来。 在网上搜、按经验找了 ~、~/Library/Preferences 等文件夹,均未找到正在使用的 2020.3 版本的配置文件。失败 此时留意到以上错误提醒里有个链接,打开链接寻找线索。 打开 https://jb.gg/ide/critical-startup-errors,在该页面并未直接找到答案,但在侧边栏发现了线索链接。 跳转到 Selecting the JDK version the IDE will run under,在正文的 macOS 部分,提到了如果配置过 IDE JDK Version,会保存在配置文件目录下的 <product>.jdk 文件里,并提供了配置文件目录相关的链接。 跳转到 Directories used by the IDE to store settings, caches, plugins and logs,可以找到 macOS 下 IDEA 2020.3 的配置文件路径 idea.config.path 为 ~/Library/Application Support/JetBrains/IntelliJIdea2020.3,打开该目录,果然发现了 idea.jdk 文件。 将 idea.jdk 文件删除,重新打开 IDEA,问题解决。 小结 当遇到问题时,最应该关注的是错误提示里的信息,很可能解决方案或线索就在里面。 如果以上解决不了问题,在官方文档/网站等渠道寻找解决方案会比盲目全网搜索更精准。如 Configuration directory 这个链接里就清楚地描述了 IntelliJ IDEA 配置文件的存放位置。
更新: 此文发到 V2EX 后,有网友指出文中的案例代码改写为 List<String> result = paramList.parallelStream().map(this::doSomething).collect(toList()); 就能很好的解决,确实如此,当时代码审查时意识到这里有线程安全问题,然后我就有点思维定势,只想着用解决线程安全问题的方式去处理,没有换个角度想到这种更好的写法。以下仍然保留原文,阅读重点可以放「线程安全」的分析理解上,parallelStream 权当为了举例而简写的一种多线程写法。实际遇上它时可以优先用 parallelStream.map().collect() 和 parallelStream.flatMap().collect() 这类方案。 以下为原正文。 本文从代码审查过程中发现的一个 ArrayList 相关的「线程安全」问题出发,来剖析和理解线程安全。 案例分析 前两天在代码 Review 的过程中,看到有小伙伴用了类似以下的写法: List<String> resultList = new ArrayList<>(); paramList.parallelStream().forEach(v -> { String value = doSomething(v); resultList.add(value); }); 印象中 ArrayList 是线程不安全的,而这里会多线程改写同一个 ArrayList 对象,感觉这样的写法会有问题,于是看了下 ArrayList 的实现来确认问题,同时复习下相关知识。 先贴个概念: 线程安全 是程式设计中的术语,指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。 ——维基百科 我们来看下 ArrayList 源码里与本话题相关的关键信息: public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable { // ... /** * The array buffer into which the elements of the ArrayList are stored. * The capacity of the ArrayList is the length of this array buffer... */ transient Object[] elementData; // non-private to simplify nested class access /** * The size of the ArrayList (the number of elements it contains). */ private int size; // ... /** * Appends the specified element to the end of this list... */ public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } // ... } 从中我们可以关注到关于 ArrayList 的几点信息: 使用数组存储数据,即 elementData 使用 int 成员变量 size 记录实际元素个数 add 方法逻辑与执行顺序: 执行 ensureCapacityInternal(size + 1):确认 elementData 的容量是否够用,不够用的话扩容一半(申请一个新的大数组,将 elementData 里的原有内容 copy 过去,然后将新的大数组赋值给 elementData) 执行 elementData[size] = e; 执行 size++ 为了方便理解这里讨论的「线程安全问题」,我们选一个最简单的执行路径来分析,假设有 A 和 B 两个线程同时调用 ArrayList.add 方法,而此时 elementData 容量为 8,size 为 7,足以容纳一个新增的元素,那么可能发生什么现象呢? 一种可能的执行顺序是: 线程 A 和 B 同时执行了 ensureCapacityInternal(size + 1),因 7 + 1 并没超过 elementData 的容量 8,所以并未扩容 线程 A 先执行 elementData[size++] = e;,此时 size 变为 8 线程 B 执行 elementData[size++] = e;,因为 elementData 数组长度为 8,却访问 elementData[8],数组下标越界 程序会抛出异常,无法正常执行完,根据前文提到的线程安全的定义,很显然这已经是属于线程不安全的情况了。 构造示例代码验证 有了以上的理解之后,我们来写一段简单的示例代码,验证以上问题确实可能发生: List<Integer> resultList = new ArrayList<>(); List<Integer> paramList = new ArrayList<>(); int length = 10000; for (int i = 0; i < length; i++) { paramList.add(i); } paramList.parallelStream().forEach(resultList::add); 执行以上代码有可能表现正常,但更可能是遇到以下异常: Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at java.util.concurrent.ForkJoinTask.getThrowableException(ForkJoinTask.java:598) at java.util.concurrent.ForkJoinTask.reportException(ForkJoinTask.java:677) at java.util.concurrent.ForkJoinTask.invoke(ForkJoinTask.java:735) at java.util.stream.ForEachOps$ForEachOp.evaluateParallel(ForEachOps.java:160) at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateParallel(ForEachOps.java:174) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:233) at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418) at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:583) at concurrent.ConcurrentTest.main(ConcurrentTest.java:18) Caused by: java.lang.ArrayIndexOutOfBoundsException: 1234 at java.util.ArrayList.add(ArrayList.java:465) at java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1384) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) at java.util.stream.ForEachOps$ForEachTask.compute(ForEachOps.java:291) at java.util.concurrent.CountedCompleter.exec(CountedCompleter.java:731) at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1067) at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1703) at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:172) 从我这里试验的情况来看,length 值小的时候,因为达到容量边缘需要扩容的次数少,不易重现,将 length 值调到比较大时,异常抛出率就很高了。 实际上除了抛出这种异常外,以上场景还可能造成数据覆盖/丢失、ArrayList 里实际存放的元素个数与 size 值不符等其它问题,感兴趣的同学可以继续挖掘一下。 解决方案 对这类问题常见的有效解决思路就是对共享的资源访问加锁。 我提出代码审查的修改意见后,小伙伴将文首代码里的 List<String> resultList = new ArrayList<>(); 修改为了 List<String> resultList = Collections.synchronizedList(new ArrayList<>()); 这样实际最终会使用 SynchronizedRandomAccessList,看它的实现类,其实里面也是加锁,它内部持有一个 List,用 synchronized 关键字控制对 List 的读写访问,这是一种思路——使用线程安全的集合类,对应的还可以使用 Vector 等其它类似的类来解决问题。 另外一种方思路是手动对关键代码段加锁,比如我们也可以将 resultList.add(value); 修改为 synchronized (mutex) { resultList.add(value); } 小结 Java 8 的并行流提供了很方便的并行处理、提升程序执行效率的写法,我们在编码的过程中,对用到多线程的地方要保持警惕,有意识地预防此类问题。 对应的,我们在做代码审查的过程中,也要对涉及到多线程使用的场景时刻绷着一根弦,在代码合入前把好关,将隐患拒之门外。 参考 线程安全——维基百科
最终的实现效果是在文件 / 文件夹上右击时,会出现菜单项「用 VSCode 打开」,点击后会启动 Visual Studio Code 打开对应的文件 / 文件夹。 实现步骤 打开「自动操作.app」,就是小机器人图标那个; command + n 新建文稿,在「选取文稿类型」里选择「快速操作」; 按以下步骤操作: 第五步贴入代码 for f in "$@" do open -a "Visual Studio Code" "$f" done 以上代码片段的大概意思是对于传入的一个或多个参数,都使用 Visual Studio Code 这个 APP 打开(将以下步骤配置完成后,可以分别选中一个、多个文件 / 文件夹,然后右键用 VSCode 打开看看效果)。 command + s 保存为 「用 VSCode 打开」: 好了,现在试试在 Finder 里右键一个文件,就可以直接看到「用 VSCode 打开」菜单,右键一个文件夹,就可以看到「服务」-「用 VSCode 打开」菜单了。 愉快地使用 Visual Studio Code 和各种文件、文件夹玩耍吧。 编辑 以后如果想修改上面这个快速操作,有两种方法: 可以打开「自动操作.app」,然后「文件」-「打开最近使用」 -「用 VSCode 打开.workflow」; 如果找不到这个操作,可以「文件」-「打开」-个人目录 / 资源库 / Services / 用 VSCode 打开.workflow 如果个人目录下不显示「资源库」,按 Command + Shift + .。 参考 https://blog.csdn.net/u013069892/article/details/83147239
之前写过一篇 使用 jsDelivr 免费加速 GitHub Pages 博客的静态资源,在那之后,又陆续想到并实施了几点利用 jsDelivr 进一步加速静态资源加载的措施,新起一篇作为记录和分享。 继上一轮改造过后,比较拖页面加载速度的主要有三点: 页面首个请求响应时间; 图片资源加载时间; 站内搜索引用的 JSON 资源加载时间。 第 1 点在页面仍然托管在 GitHub Pages 的前提下,似乎没有什么好办法能产生质的飞跃;本篇主要改善了第 2 点和第 3 点。 0x01 图片资源加速 这里所说的图片主要是指文章里引用的图片。 我一直将图片放在博客源码根目录的 images 文件夹下,引用图片的习惯写法是这样的: 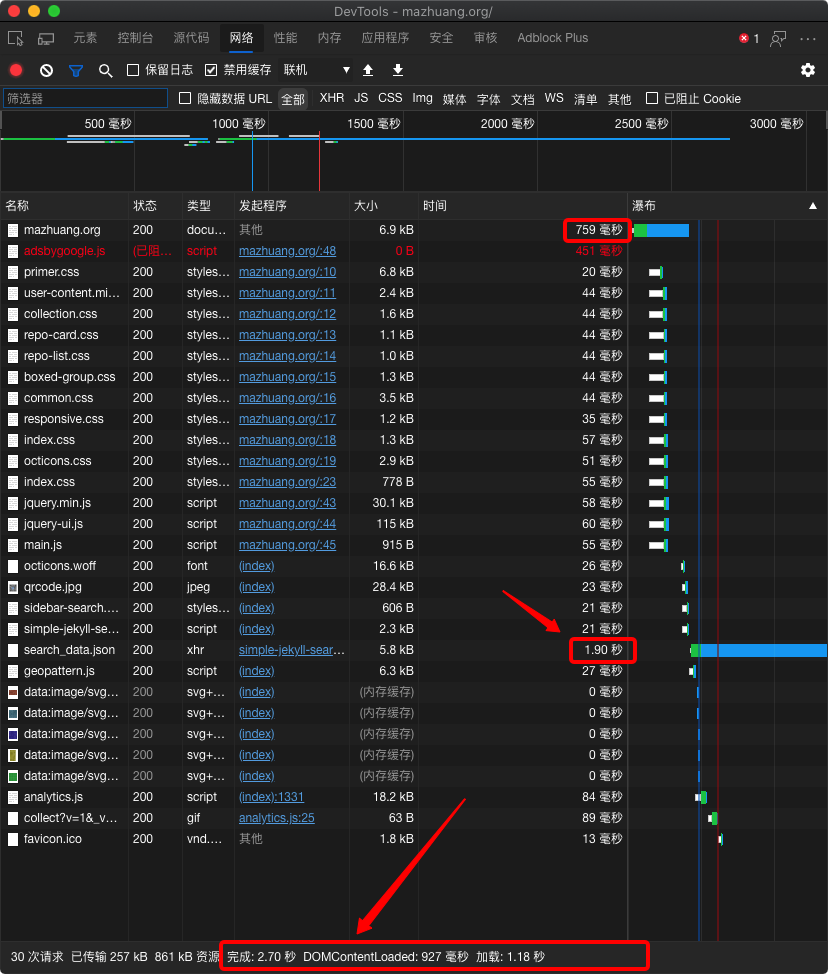 如果想将这个图片地址替换为 jsDelivr 的地址,需要做的就是将 /images 替换为 https://fastly.jsdelivr.net/gh/mzlogin/mzlogin.github.io@master/images。 一处一处替换行不行?当然也行,但后面写新文章时要引用图片,还得手动写这一长串,不方便;万一 jsDeliver 出状况,也不好一键切换回来。有没有一劳永逸的方法?当然也有,我们从 Jekyll 的 layout 机制来想办法。 Jekyll 的 layout 可以理解为页面模板,它是可以继承的,比如我的博客的所有页面模板有一个共同的祖先模板 _layouts/default.html,模板里可以使用 Liquid 语法对内容进行处理,我们可以利用这一点,来自动完成批量替换的工作。 关键代码如下: {% assign assets_base_url = site.url %} {% if site.cdn.jsdelivr.enabled %} {% assign assets_base_url = "https://fastly.jsdelivr.net/gh/" | append: site.repository | append: '@master' %} {% endif %} {% assign assets_images_url = 'src="' | append: assets_base_url | append: "/images" %} {% include header.html %} {{ content | replace: 'src="/images', assets_images_url }} {% include footer.html %} 大意就是,如果打开了启用 jsDelivr 加速的开关,就将 content 里的 src="/images" 替换为 src="https://fastly.jsdelivr.net/gh/mzlogin/mzlogin.github.io@master/images",否则替换为 src="https://mazhuang.org/images"。 以上便达成了我们的目的。 0x02 站内搜索引用的 JSON 资源加速 我是使用 Simple-Jekyll-Search 这个 JavaScript 库来实现站内搜索的,它的搜索数据是来自一个动态生成的 JSON 文件。 这个 JSON 文件编译前长这样: https://github.com/mzlogin/mzlogin.github.io/blob/master/assets/search_data.json Jekyll 编译后长这样: https://mazhuang.org/assets/search_data.json 这样的资源是没有办法直接通过替换网址来用 jsDelivr 加速的,因为 jsDelivr 上缓存的是编译前的文件,而我们需要的是编译后的。 那我们就想办法: 将博客源码编译; 将编译结果保存到另一个分支; 通过 jsDelivr 引用新分支上的这个文件。 这些步骤可以通过 GitHub 去年推出的新特性 Actions 来完成,在我们每一次向博客源码仓库 push 代码时自动触发。 关键步骤如下: 在 GitHub 新建一个 Personal access Token: Settings –> Developer settings –> Personal access tokens –> Generate new token –> 填写 note,勾选 public_repo,生成之后复制 token 值备用。 在博客源码仓库的 Settings –> Secrets –> New secret,Name 填 ACCESS_TOKEN,Value 填第 1 步里复制的 token 值; 在博客源码根目录下新建文件 .github/workflows/ci.yml,内容如下: name: Build and Deploy on: push: branches: [ master ] jobs: build-and-deploy: runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v2.3.1 with: persist-credentials: false - name: Set Ruby 2.7 uses: actions/setup-ruby@v1 with: ruby-version: 2.7 - name: Install and Build run: | gem install bundler bundle install bundle exec jekyll build - name: Deploy uses: JamesIves/github-pages-deploy-action@3.6.2 with: ACCESS_TOKEN: $ BRANCH: built FOLDER: _site CLEAN: true 大意就是在向 master 分支 push 代码时,自动执行 checkout、初始化 ruby 环境、安装 Jekyll 并编译博客源码的工作,最后将编译生成的 _site 目录里的内容推送到 built 分支。对 GitHub Actions 感兴趣的同学可以自行参考官方说明学习。 修改引用 JSON 文件的地方,比如我的 _includes/sidebar-search.html 里的写法由: json: '/assets/search_data.json', 改为了 {% if site.cdn.jsdelivr.enabled and site.url contains 'mazhuang.org' %} json: 'https://fastly.jsdelivr.net/gh/mzlogin/mzlogin.github.io@built/assets/search_data.json', {% else %} json: '{{ site.url }}/assets/search_data.json', {% endif %} 将以上更改推送到源码仓库,等待处理完成即可。 0x03 结语 经过以上改造,博客页面的加载速度又得到了小小的提升,所有相关源码可以在 https://github.com/mzlogin/mzlogin.github.io 找到,有相关心得或建议的朋友欢迎交流指正。 相关文章: 使用 jsDelivr 免费加速 GitHub Pages 博客的静态资源
昨天朋友圈和微博上有不少人在转发林丹从国家队退役的消息,有一点感慨的同时,我在想,以后新入坑的羽毛球迷们,可能渐渐就都不知道「超级丹」、「林李大战」,还有「四大天王」这些名词了吧。 不过没有关系,一代人有一代人的关注点,新时代总会诞生新的偶像,就像去年周杰伦和蔡徐坤的粉丝在微博刷超话,这样的场景怕是没少发生过,场面有大有小罢了。 这一篇不讲林丹的事,讲一些我与羽毛球之间的那些可以不说的碎碎念。 入坑的过程 羽毛球在国内可能是仅次于乒乓球的国民运动了,小时候哥哥姐姐们就有时候会在门口的空地上打一会儿,而我开始打羽毛球比较晚,是在参加工作以后了。 依照工作地点变迁的线: 十堰 第一家公司东风汽车有着浓厚的羽毛球氛围,据说与时任董事长热爱这项运动有关。当时一起入职的小伙伴们有些就此入坑,而我那时候,一方面主要运动还是偶尔打一打篮球,另一方面,因为以前基本没打过,去过几次总是接不到球感觉很丢脸,所以参与意愿也比较淡薄。 北京 我的「羽毛球生涯」可以说正式开端于北漂期间,那时候跟同学们闲聊起各自公司里的业余活动,发现羽毛球很流行,推测可能是因为身体冲撞少,相比篮球足球受伤的风险更低。在蹭了同学公司的几次活动之后,萌生了一些兴趣,在入职前东家搜狗前几天,跟几个同学一起去买了球拍,打算偶尔组一局。 然后在前东家发现项目组里的测试童鞋们正谋划组织羽毛球活动,于是果断报名参加。刚开始也是各种接不到球、挥拍挥空,好在这时候逐渐学会了一点自嘲,终于没有退缩,坚持了下来。在这期间刷了一阵李在福的《追球》系列教学视频,对基础技术有了系统一点的了解。再后来就是参加公司和集团俱乐部的活动,基本每周都去清华气膜馆打,从被新手虐慢慢过渡到了能虐新手,然后……水平就止步不前了。 在那段时期还加了回龙观地区的民间组织情怀羽毛球俱乐部,周末偶尔到回龙观中学被虐一虐。 武汉 加入现东家震坤行后,我从公司羽毛球活动的参与者变成了主要组织者。武汉这边是分部,办公室人数一直不多,从开始的二十来号人到现在的一百多号人,组起一场球来依然不容易。 以前周末主要是和光谷社区结识的一群小伙伴一起打球,疫情后的这段时间,又组了一个「问道软件园,养生羽毛球」的群,聚集了光谷软件园几个公司的一些有热爱的小伙伴工作日下班后继续活动。 收获 长期坚持一项运动收益良多,说一说我体会比较深的几个方面。 健康 从事上班时久坐不动的工作,几年之后体检,基本很少有腰椎颈椎没有毛病的。坚持打羽毛球是一种比较好的预防和缓解的方法。 再就是,几天的工作里可能有比较烦闷的事情积攒下来,通过运动能及时把这口闷气排解出来,有时候感觉每周的这一场球就是生活的寄托了。 社交 能坚持一项爱好的一般都是不错的人,在羽毛球这个圈子更是。 通过参与公司、民间组织的活动,我结识了不少优秀的小伙伴,一起享受运动和生活的乐趣,必要时也能相互提供其它方面的帮助。 我一直建议身边的年轻人们要有一项爱好,融入对应的圈子。特别建议坚持来打球,能认识一群不错的朋友不说,说不定人生的另一半也能在球场相遇,我们起源于光谷社区的约球小群里,19 个人成就了 3 对情侣的事一直被津津乐道,这可比各种相亲活动靠谱多了。 性格与心态 我说我是一个内向的人有很多人不信,但确实就是这样。以前是什么程度呢?上大学英语课时被老师点起来回答个问题脸能红到耳朵根,有个什么事情要找女生说,要在心里鼓好一阵的勇气。现在脸皮稍厚了一点,但内向依旧对我影响深远。 这样的我有一个缺陷,那就是在擅长的方面会表现得比较自信,也比较愿意去表现,而不擅长的方面就会尽量退避。这在有些时候没有问题,但在职场上,积累得多了可能就会给人一种态度不积极的印象。 学打羽毛球的过程,对我而言,也是一个磨炼心性的过程,从开始的接不到球、挥空拍时大家善意的嘲笑,到熟能生巧与一些业余球友可以一战,这中间我克服了一些怯懦,建立了一些自信——不擅长的方面,通过练习是可以入门和加强的。 资源 最后推荐一个我觉得不错的学习资源吧,作为野路子出身系统入门挺好: 李在福《追球》全集:https://v.youku.com/v_show/id_XMjczOTAyODI4.html
我们可能都听过一句话: 吾生也有涯,而知也无涯。以有涯随无涯,殆已!——《庄子. 内篇. 养生主第三》 所以,需要持续大量学习的童鞋,比方说我等程序员们,除了要从知识的海洋中精挑细选出我们想要的内容,挑完了还得高效学习,不然成长的速度可能远远赶不上脱发的速度,沦落到「他变秃了,也没变强」的尴尬境地。 更聪明地学习,而不是苦读——这是我打开 Kindle for Mac 后看到的第一句话,最近读的这本 《如何高效学习》 正是一本关于此话题的书。 关于本书 作者 Scott H. Young,这哥们是个神人,超级学霸,比较广为人知的事迹是他的 MIT Challenge,用一年的时间自学完 MIT 计算机专业四年 33 门课程(当然,他不是 MIT 的学生,没有拿到学位)。有关他的更多信息可以访问 Scott H. Young 了解。 这本书里就是介绍他自己总结的学习方法,主要就是所谓「整体性学习」。 在开始读书笔记之前我忍不住要先来一段吐槽。 前置吐槽 这本书的英文原书名为 Learn More, Study Less,豆瓣评分 8.0,中文版叫 《如何高效学习》,豆瓣评分 7.4,这中间差的 0.6 分,看了一些书评,我估计很多读者会认为是被译者吃了,豆瓣上有好些网友在 跪求译者不要再译书了。:cry: 我……也有点这种感觉。奈何我啃英文太慢了,所以还是先看了中文版,然后才找到原著对照理解了部分内容,英文阅读水平还行的同学建议直接读原著。 以下是我阅读中文版过程中想吐槽的一些点: 过多不必要的「译者注」,而且是放在正文里的; 比如这里,整整一页的译者注,但实际注解得并不好,也无必要。 适当的留白和思考空间留给读者自己可能更好。 「导读」里花了几页来讲的「吃饭模型学习法」,可以看出是想应用书中大力推崇的比喻,但用得牵强附会了,并无助于理解,放在书的开头反而让人纳闷; 同一个场景下的同一名词,在书中有不同的翻译; 比如整体学习的五个阶段里的第二阶段有时被翻译为「理解」,有时被翻译为「明白」。 有翻译错误 / 不准确的情况; 比如,整体学习的五个阶段,这是非常重要的信息,但是,原文: Explore - The Explore Phase is really where holistic learning takes full force. Here you form the models, highways and broader connections needed for well defined constructs. 译文: 拓展 - 拓展阶段是整体性学习中最花力气的地方,这一步将形成模型、高速公路和广泛和联系,从而获得良好的结构。 我得说,这真不如机器翻译的: 正文中有一些关于学习医学的例子,原著中并没有,是译者自行添加的。 好了吐槽完毕,记笔记记笔记。 读书笔记 摘录 所谓的聪明是指能学得更快、记得更多更牢,而且信息的组织非常适合完成自己的目标。——Scott H. Young 对聪明的定义 整体性学习的基础就是将知识关联起来以达到记忆和应用知识的目的,开始学习的最佳技术是比喻、内在化、基于流程的记事和画图表法,这些方法构成了整体性学习的基础。 要想超出知识本身,光有热情还不够,你要寻找各种应用知识的途径(即使现在讨厌它),知识因“用”而获得新的意义。 比喻就是在不熟悉的知识和熟悉的知识之间架起一座沟通的桥梁。 莱考夫把隐喻定义为“以一种事物认知另一种事物”,而这恰恰就是学习的本质。 知识点 整体性学习相关的概念 机械记忆 VS 整体性学习——死记硬背 VS 将各种知识相互关联,建立信息的网络。 整体性学习基于三个主要思想: 结构:结构就是一系列紧密联系的知识;(城市) 模型:模型是结构的快照,更为简单和更易储存;(结构的抽象) 模型有很多种形式,但是目标总是同样的:那就是压缩信息。 高速公路:结构与结构之间的联系;(城市之间的高速公路) 整体性学习的阶段与顺序: 信息结构(分类): Scott 将信息作以下分类,学习新的知识时,首先判断信息主要属于哪一类,然后采取对应的处理方法。 整体性学习的技术 作者在书中也多次提到,这些技术如果只是了解而不去练习和实践,是没有什么用的。书中提供了很多「智力挑战」,具体请参考原著。 Part 1 获取知识 一、快速阅读 指读法 对就是你想的那个指读法。 练习阅读法 类似我们以前做阅读理解的练习,目的是训练自己以尽可能快的速度理解所读内容。 积极阅读法 强调深入地理解材料,类似于所谓「精读」,每读完一小部分都对应做一些笔记。 积极阅读时带着三个问题: 这部分的主要知识点是什么? 怎样才能记住主要知识点?(联系、视觉化和比喻) 怎样将知识点应用到实际情境中? 二、笔记流 尽量简短地写下主要知识点(找重点),然后用箭头将它们联系起来,可以结合简易图像、表格。 Part 2 联系观点 主要处理困难信息(抽象信息、随意信息等)和关键信息(构成学习其它知识的基础)。 一、比喻 在不熟悉的知识和熟悉的知识之间架起一座沟通的桥梁。 二、内在化 调用各种感知与知识联系在一起,比如视觉(脑海中出现图像)、听觉、触觉和情感等。 三、简图法 将多个信息压缩成一幅简图。主要可以借助流程图(步骤、脑图)、概念图(知识点及联系)和涂鸦。 Part 3 随意信息的处理 一、联想法 将一系列知识点串连在一起,就像链条,一旦进入链条中的一环,就可以轻易地到达链条中的其它环节。 二、挂钩法 建立你自己的基本数字字典,然后将要记忆的信息与这些数字联系在一起,再查字典用数字的含义编一个小故事。(这玩意作为一个记忆方法太绕了,是否真有人这样用我表示怀疑) 三、信息压缩技术 储存大量随意信息的方法,目标是精简信息,寻找逻辑关系。 三种方法: 记忆术——用一个短语或者单词来储存数个信息的方法。 如用各单词的首字母拼成一个简单通用的短语或单词。 图像联系——我感觉同上面提到的「简图法」。 笔记压缩——将很多知识压缩到几页笔记里,试图快速掌握大量材料。 用小字将主要知识点及与之相联系的重要内容写下来,结合简图。 Part 4 知识扩展 一、实际应用 总是努力把知识应用于实际,会记得更牢。 比如:在一堆东西里快速找到想要的那个,可以考虑用二分法。 二、模型纠错 在练习和实践中发现问题、纠正问题。 三、基于项目的学习 设定一个合适大小的目标,做好计划,围绕着目标学习。 作者的几点建议: 目标不要太大,可以试试 1-3 个月的项目; 将工作进度和过程记录下来,看着已经完成的工作可以增强信息和继续下去的欲望; 目标要有意义。 费曼技巧 这部分貌似在英文原著里没有,但我觉得挺重要的。 简而言之,就是假设你要给一名小白讲解这个知识点,用尽量简洁的表述让他听懂,如果有不知道如何表述的地方,那就回过头把它搞懂。 让我想起不知道在哪看的一句话:「我讲的你听懂了,代表我掌握了,不是你」。 还想起是不是华罗庚也经常用这个法子…… 超越整体性学习 一、高效秘籍 二、自我教育 一些自我教育的网上资源: MIT OpenCourseWare EHow.com FreeEd.net Portal to Free Online Courses 书籍和网站 书中提到了很多书籍,在第三部分的最后一节里也列举了一些高效率相关的网址和书籍,收集如下: 书籍 Breakthrough Rapid Reading 我们赖以生存的隐喻 Getting Things Done The Power of Full Engagement Zen To Done How to Become a Straight-A Student How to Win at College 网址 ScottHYoung.com ZenHabits.net Lifehack.org PickTheBrain.com StudyHacks StevePavlina.com 参考 https://book.douban.com/subject/25783654/ https://book.douban.com/subject/11603298/ https://www.zhihu.com/question/20571226 https://www.scotthyoung.com/blog/myprojects/mit-challenge-2/#6 https://www.scotthyoung.com/ https://www.zhihu.com/question/23043048 https://www.zhihu.com/pub/book/119554615 https://www.scotthyoung.com/blog/2008/02/06/20-tips-for-batching-to-save-time-and-cut-stress/
我习惯使用 Vim 编辑 Markdown 文件,一直存在一个痛点就是粘贴图片很不方便。 前后对比 我以前常用的操作流程: 复制图片/截图; 在保存图片对话框里一层层点选保存路径,输入文件名保存; 回到 Vim 里,手动输入引用图片的表达式。 第 2 步和第 3 步是比较痛苦的,尤其是文件路径比较深的时候,可能要点选好几次。 最近偶然发现的一个外国小伙写的插件 md-img-paste.vim1,能比较好地解决这个问题。现在的操作流程: 复制图片/截图; 在 Vim 里输入图片相对路径,自动保存图片并插入引用图片的表达式。 注:也可以直接回车,会按默认规则生成文件名。 效果演示: 使用方法 安装 这个插件没有其它依赖,使用自己习惯的插件管理方式安装就好。 比如我使用 Vundle2,在 vimrc 里添加如下内容,然后 :so $MYVIMRC 再 :PluginInstall 就好了。 Plugin 'ferrine/md-img-paste.vim' 配置 插件没有给粘贴剪贴板里的图片的操作绑定默认快捷键,需要自己绑定一下,比如我是绑定到 \<leader\>i: autocmd FileType markdown nmap <buffer><silent> <leader>i :call mdip#MarkdownClipboardImage()<CR> 另外还有两个可选配置项: let g:mdip_imgdir = '.' " let g:mdip_imgname = 'image' g:mdip_imgdir 对应图片保存路径前缀。我设置为了 .,然后总是输入相对当前文件的路径; g:mdip_imgname 对应图片保存时的缺省文件名前缀,即粘贴图片时,如果不输入文件名直接回车,将保存为 <前缀>_日期-时间.png 名称的文件。 我的完整 Vim 配置文件托管在 GitHub3,供参考。 It’s done, enjoy it. https://github.com/ferrine/md-img-paste.vim ↩ https://github.com/VundleVim/Vundle.vim ↩ https://github.com/mzlogin/config-files/blob/master/_vimrc ↩
挺久以前就有网友给我的 GitHub Pages 博客模板提 Issue,说希望能增加 CDN 用于加速静态资源的加载,由于懒,一直没有动。 最近偶尔要打开自己博客看下 Wiki 的时候,要等挺久,比较痛苦,碰巧昨天晚上看到这样一篇帖子:GitHub 图床的正确用法,通过 jsDelivr CDN 全球加速,感觉很适合我的需求场景,于是决定趁这几天休假将这个改造一下。 先看效果 以下改造前后的加载情况都是在 Edge 浏览器禁用缓存后录制的,录制时间段很接近,从本地访问两个 GitHub Pages 服务的原始响应速度应该类似。 改造前加载 注:由于改造前没有保留加载图,所以这是截的一个使用相同模板的朋友的首页加载情况。 可以看到耗时最长的两个请求时间达到了 12 秒左右,而且很多资源的加载时间在 1 秒以上,页面完成加载时间长达 15 秒多……估计一般的访客是没这个耐心等待的。 改造后加载 这样一对比效果还是很明显的。改造过后耗时最长的是两个没办法走 CDN 的请求,而走 CDN 的那些资源加载时间基本都没超过 60 毫秒,页面完成加载时间缩短到了 3 秒以内。 当然,因为页面自身还是在 GitHub Pages 托管,有时候首个请求还是会挺久才返回。 改造后的效果可以打开 https://mazhuang.org 体验。 方案考虑 优化独立博客的加载速度有一些不同的思路,对应不同的方案: 优化博客代码,精简需要加载的资源; 将博客部署到国内访问快的服务器上; 部署到国内的代码托管平台,比如 Gitee 和 Coding 等; 采用 CDN 加速; 等等。 其中 2 和 3 我不想考虑,还是期望只在 GitHub 上管理博客,所以 1 和 4 是优化方向,本文对应的就是 4 的部分。 而采用 CDN 加速的方案,可以考虑 将公共库改为直接引用公共 CDN 链接; 自己编写和修改的静态资源自己去托管在一个 CDN 服务上。 有一些 CDN 服务商提供一定的免费额度,可以按喜好选用,或者选择付费服务。这里我没有纠结,看完文首提到的那篇文章,去看了下 jsDelivr 的介绍后觉得靠谱:它原生支持使用 GitHub 项目里的资源,什么都不用配置,更重要的是免费,在国内有节点,而且速度还不错(官网上也把 works in China 作为一个卖点的),遂决定直接用它。 jsDelivr 支持的 GitHub 资源的方式 jsDelivr 对 GitHub 的支持是作为重要特性来宣传的,官网的介绍链接:https://www.jsdelivr.com/features#gh,以下是一些认为需要了解的知识的小结: 这里以我托管博客的 GitHub 仓库为例,地址是 https://github.com/mzlogin/mzlogin.github.io,那它里面的资源可以直接以 https://fastly.jsdelivr.net/gh/mzlogin/mzlogin.github.io/ + 仓库里的文件路径 来访问。 比如仓库里有一个 js 文件 assets/js/main.js,那么它可以用 CDN 链接 https://fastly.jsdelivr.net/gh/mzlogin/mzlogin.github.io/assets/js/main.js 来访问。 另外还支持一些高级用法,比如: 指定 release 版本号/提交 sha1/分支名称,例如指定获取该仓库的名称为 1.2.0 或 v1.2.0 的 release 版本资源: https://fastly.jsdelivr.net/gh/mzlogin/mzlogin.github.io@1.2.0/assets/js/main.js 如果指定版本为 1 或者 1.2,那它会自动匹配到这个范围内的最新版本号。 也可以不指定版本或者指定版本为 latest,这样总是使用最新版本的资源。 压缩资源,在 js/css 文件后缀前面加上 .min: https://fastly.jsdelivr.net/gh/mzlogin/mzlogin.github.io@1.2.0/assets/js/main.min.js 合并多个文件,用 combine/file1,file2,file3 格式的链接: https://fastly.jsdelivr.net/combine/gh/mzlogin/mzlogin.github.io@1.2.0/assets/js/main.min.js,gh/mzlogin/mzlogin.github.io@1.2.0/assets/js/simple-jekyll-search.min.js 压缩资源、合并文件的 CDN 链接在第一次有人访问时可能比较慢,后面再有人访问就快了。 其它知识点: 可以通过 https://fastly.jsdelivr.net/combine/gh/mzlogin/mzlogin.github.io[@<版本号>]/[<文件夹>/] 这样的路径浏览缓存文件列表; 可以访问 https://purge.jsdelivr.net/gh/mzlogin/mzlogin.github.io@1.2.0/assets/js/main.js 来清除指定文件的缓存;(将引用的 CDN 链接里的 cdn 改成 purge 就是了) 可以访问 https://data.jsdelivr.com/v1/package/gh/mzlogin/mzlogin.github.io 来查看 CDN 上的 tags 和 versions 列表,更多数据接口参数参见 https://github.com/jsdelivr/data.jsdelivr.com。 改造步骤 下面是记录具体改造博客模板的步骤: 在 _config.yml 文件中添加控制开关: # 对 css 和 js 资源的 cdn 加速配置 cdn: jsdelivr: enabled: true 修改 _layouts 里的文件,给名为 assets_base_url 的变量赋值,用它来代表加载静态资源的根路径: {% assign assets_base_url = site.url %} {% if site.cdn.jsdelivr.enabled %} {% assign assets_base_url = "https://fastly.jsdelivr.net/gh/" | append: site.repository | append: '@master' %} {% endif %} 修改以前直接用 {{ site.url }} 拼接的静态资源引用链接,替换为 {{ assets_base_url }},比如 _includes/header.html 里: - <link rel="stylesheet" href="{{ site.url }}/assets/css/posts/index.css"> + <link rel="stylesheet" href="{{ assets_base_url }}/assets/css/posts/index.css"> 这样万一哪天 CDN 出了点什么状况,我们也可以很方便地通过一个开关就切回自已的资源链接恢复服务。 主要就是这类修改,当然涉及的地方有多处,以上只是举一处例子记录示意,改造过程和改造后的代码可以参考我的博客仓库 https://github.com/mzlogin/mzlogin.github.io。 现存问题 如果项目曾经打过 tag,那么新增/修改静态资源后,需要刷新 CDN 缓存的话,需要打个新 tag; 一般发生在修改了博客模板的 js/css 以后。我也还在摸索如何省去这一步的方法。 Update: 我后来采用的解决方法是删除了所有的 tag,这样以前的 release 就变成了 Draft,对外是不可见的,因为我这个仓库不需要对外可见的 release,所以这个问题也就解决了,不需要再操心刷新 CDN 的问题了。 参考链接 GitHub 图床的正确用法,通过 jsDelivr CDN 全球加速 jsDelivr 为开发者提供免费公共 CDN 加速服务 Features - jsDelivr 相关文章 使用 jsDelivr 免费加速 GitHub Pages 博客的静态资源(二)
书接上回,在 记一个 Base64 有关的 Bug 一文里,我们说到了 Base64 的编解码器有不同实现,交叉使用它们可能引发的问题等等。 这一回,我们来对 Base64 这一常用编解码技术的原理一探究竟。 1. Base64 是什么 Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法。由于 2^6=64,所以每 6 个比特为一个单元,对应某个可打印字符。3 个字节有 24 个比特,对应于 4 个 Base64 单元,即 3 个字节可由 4 个可打印字符来表示。 ——维基百科 它不是一种加解密技术,是一种简单的编解码技术。 Base64 常用于表示、传输、存储二进制数据,也可以用于将一些含有特殊字符的文本内容编码,以便传输。 比如: 在电子邮件的传输中,Base64 可以用来将 binary 的字节序列,比如附件,编码成 ASCII 字节序列; 将一些体积不大的图片 Base64 编码后,直接内嵌到网页源码里; 将要传递给 HTTP 请求的参数做简单的转换,降低肉眼可读性; 注:用于 URL 的 Base64 非标准 Base64,是一种变种。 网友们在论坛等公开场合习惯将邮箱地址 Base64 后再发出来,防止被爬虫抓取后发送垃圾邮件。 2. Base64 编码原理 标准 Base64 里的 64 个可打印字符是 A-Za-z0-9+/,分别依次对应索引值 0-63。索引表如下: 编码时,每 3 个字节一组,共 8bit*3=24bit,划分成 4 组,即每 6bit 代表一个编码后的索引值,划分如下图所示: 这样可能不太直观,举个例子就容易理解了。比如我们对 cat 进行编码: 可以看到 cat 编码后变成了 Y2F0。 如果待编码内容的字节数不是 3 的整数倍,那需要进行一些额外的处理。 如果最后剩下 1 个字节,那么将补 4 个 0 位,编码成 2 个 Base64 字符,然后补两个 =: 如果最后剩下 2 个字节,那么将补 2 个 0 位,编码成 3 个 Base64 字符,然后补一个 =: 3. 实现一个简易的 Base64 编码器 讲完原理,我们就可以动手实现一个简易的标准 Base64 编码器了,以下是我参考 Java 8 的 java.util.Base64 乱写的一个 Java 版本,仅供参考,主要功能代码如下: public class CustomBase64Encoder { /** * 索引表 */ private static final char[] sBase64 = { 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/' }; /** * 将 byte[] 进行 Base64 编码并返回字符串 * @param src 原文 * @return 编码后的字符串 */ public static String encode(byte[] src) { if (src == null) { return null; } byte[] dst = new byte[(src.length + 2) / 3 * 4]; int index = 0; // 每次将 3 个字节编码为 4 个字节 for (int i = 0; i < (src.length / 3 * 3); i += 3) { int bits = (src[i] & 0xff) << 16 | (src[i + 1] & 0xff) << 8 | (src[i + 2] & 0xff); dst[index++] = (byte) sBase64[(bits >>> 18) & 0x3f]; dst[index++] = (byte) sBase64[(bits >>> 12) & 0x3f]; dst[index++] = (byte) sBase64[(bits >>> 6) & 0x3f]; dst[index++] = (byte) sBase64[bits & 0x3f]; } // 处理剩下的 1 个或 2 个字节 if (src.length % 3 == 1) { int bits = (src[src.length - 1] & 0xff) << 4; dst[index++] = (byte) sBase64[(bits >>> 6) & 0x3f]; dst[index++] = (byte) sBase64[bits & 0x3f]; dst[index++] = '='; dst[index] = '='; } else if (src.length % 3 == 2) { int bits = (src[src.length - 2] & 0xff) << 10 | (src[src.length - 1] & 0xff) << 2; dst[index++] = (byte) sBase64[(bits >>> 12) & 0x3f]; dst[index++] = (byte) sBase64[(bits >>> 6) & 0x3f]; dst[index++] = (byte) sBase64[bits & 0x3f]; dst[index] = '='; } return new String(dst); } } 这部分源码我也上传到 GitHub 仓库 https://github.com/mzlogin/spring-practices 的 base64test 工程里了。 4. 其它知识点 4.1 为什么有的编码结果带回车 在电子邮件中,根据 RFC 822 规定,每 76 个字符需要加上一个回车换行,所以有些编码器实现,比如 sun.misc.BASE64Encoder.encode,是带回车的,还有 java.util.Base64.Encoder.RFC2045,是带回车换行的,每行 76 个字符。 4.2 Base64 的变种 除了标准 Base64 之外,还有一些其它的 Base64 变种。 比如在 URL 的应用场景中,因为标准 Base64 索引表中的 / 和 + 会被 URLEncoder 转义成 %XX 形式,但 % 是 SQL 中的通配符,直接用于数据库操作会有问题。此时可以采用 URL Safe 的编码器,索引表中的 /+ 被换成 -_,比如 java.util.Base64.Encoder.RFC4648_URLSAFE 就是这样的实现。 5. 参考链接 https://zh.wikipedia.org/zh-hans/Base64 https://www.liaoxuefeng.com/wiki/897692888725344/949441536192576 我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=guk42yjsce8s